🔥 Effective Training Data Synthesis for Improving MLLM Chart Understanding
ICCV 2025 (poster)
✨ Abstract
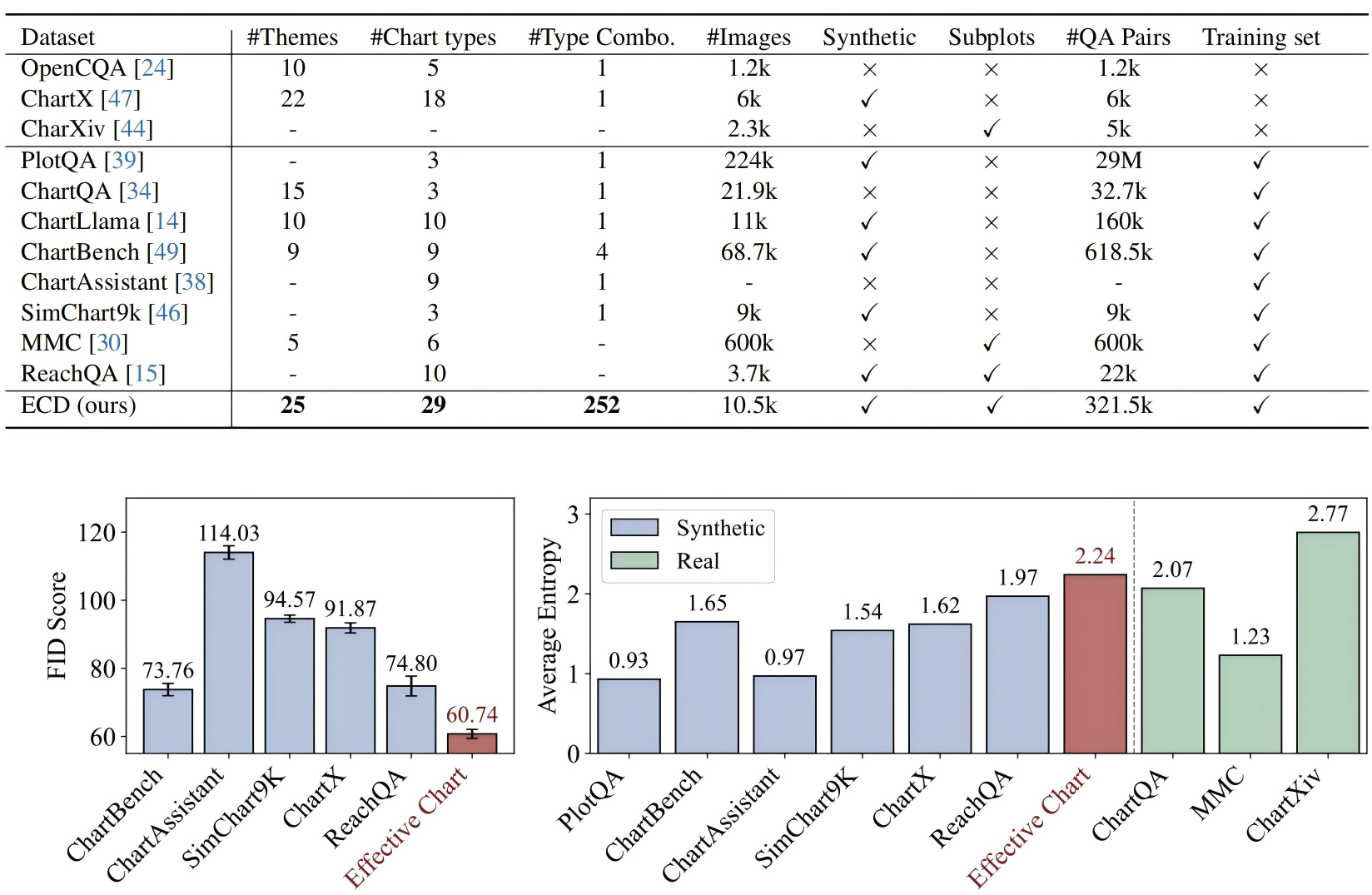
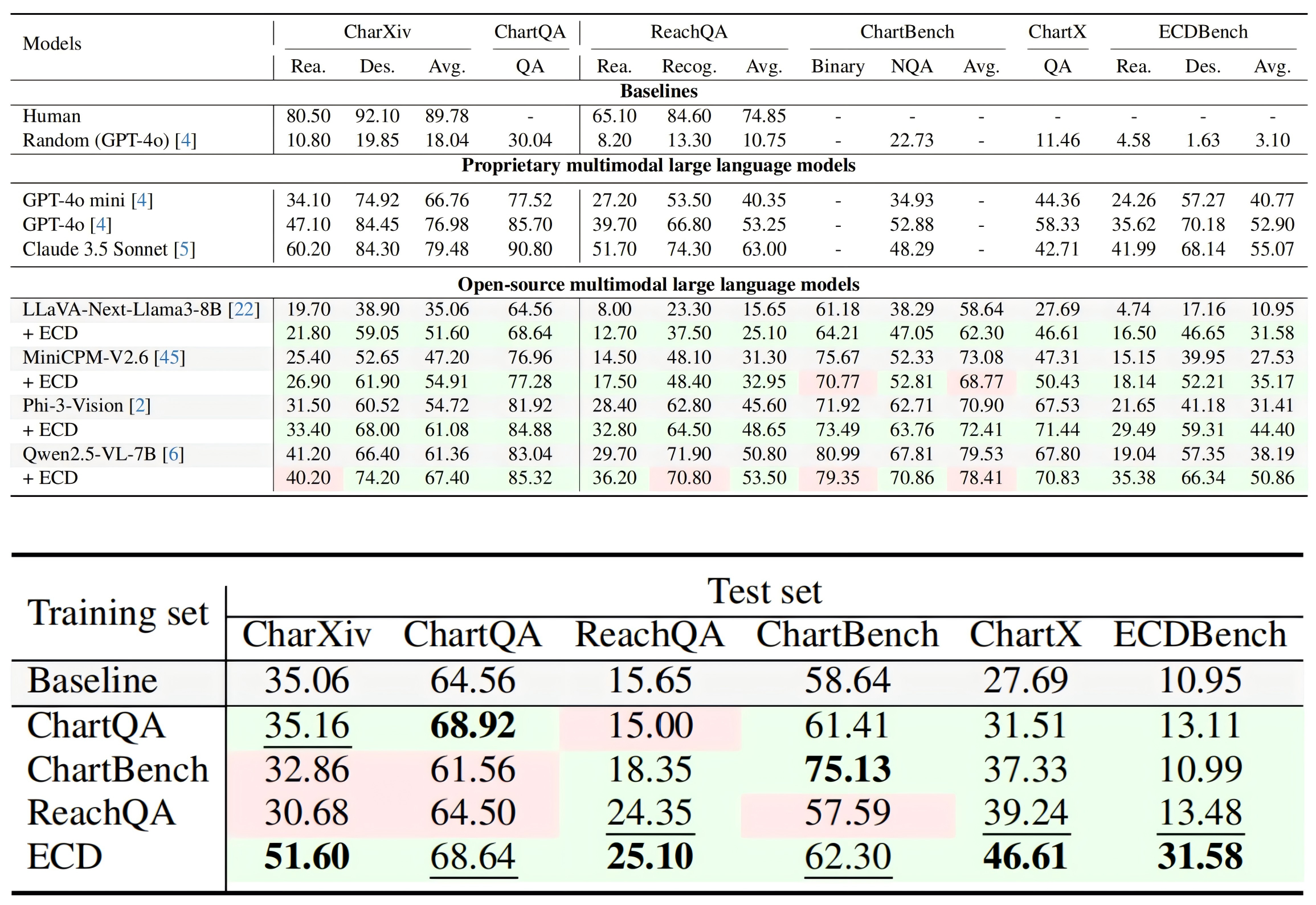
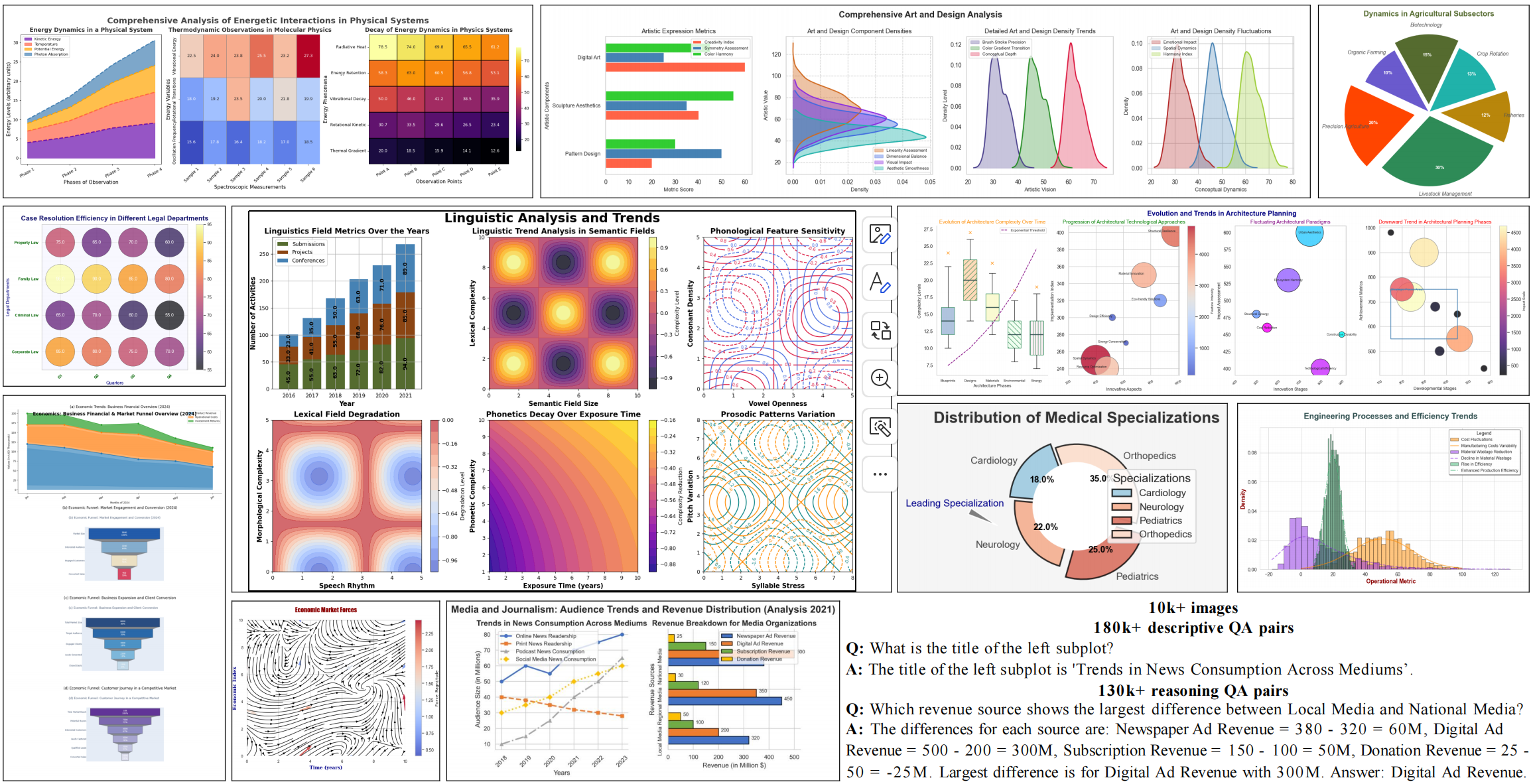
Being able to effectively read scientific plots, or chart understanding, is a central part toward building effective agents for science. However, existing multimodal large language models (MLLMs), especially open-source ones, are still falling behind with a typical success rate of 30%-50% on challenging benchmarks. Previous studies on fine-tuning MLLMs with synthetic charts are often restricted by their inadequate similarity to the real charts, which could compromise model training and performance on complex real-world charts. In this study, we show that modularizing chart generation and diversifying visual details improves chart understanding capabilities. In particular, we design a five-step data synthesis pipeline, where we separate data and function creation for single plot generation, condition the generation of later subplots on earlier ones for multi-subplot figures, visually diversify the generated figures, filter out low quality data, and finally generate the question-answer (QA) pairs with GPT-4o. This approach allows us to streamline the generation of fine-tuning datasets and introduce the Effective Chart Dataset (ECD), which contains 10k+ chart images and 300k+ QA pairs, covering 25 topics and featuring 250+ chart type combinations with high visual complexity. We show that ECD consistently improves the performance of various MLLMs on a range of real-world and synthetic test sets.